
Security brain says collect everything.
Infrastructure brain says please do not light the collector on fire.
I got a useful reminder of that while tightening up my LAN logging pipeline. The goal was simple: ship more system logs into Loki, make Grafana more useful, and stop leaving useful signal stranded on individual machines.
That is the right instinct for logging and security work.
You cannot query what you never collected.
But “more logs” is not automatically “better observability.”
Sometimes more logs are just a denial-of-service attack you launched against yourself.
The Setup
The pipeline is intentionally boring:
LAN syslog sources → Fluent Bit collector → Loki → GrafanaIn my case, the collector is a Fluent Bit LXC on Proxmox. It accepts LAN syslog, parses it, and forwards it to a Loki LXC. Grafana sits on top as the query and dashboard layer.
That part worked.
The rough shape looked like this:
pi5/ tvauto media stack shipping Docker logs over UDP syslog- other LAN syslog sources using RFC3164 or RFC5424
- Fluent Bit collecting on
5140,5141, and a few related inputs - Loki storing the logs
- Grafana querying Loki
- Prometheus marked as a future scrape path, not part of the current syslog ingest path
Clean enough.
Then I tried to improve macOS logging.
macOS Made Me Greedy
Classic /var/log on macOS does not give you the same simple, obvious firehose you might expect from a Linux box.
So I added syslog-ng to pull more useful system logging out of the Mac and forward it into the same LAN logging stack.
The motivation was reasonable:
- better local visibility
- more security-relevant events
- fewer blind spots
- one place to search across machines
In theory, this was exactly what the pipeline was built for.
In practice, I had just introduced a noisy source with enough replay and backlog risk to topple the collector.
The Failure Mode
The Mac-side source is currently disabled, but the risk became obvious once I drew the whole path:
macOS syslog-ng backlog
→ Fluent Bit parser warnings
→ memory pressure
→ OOM kill
→ stopped LXCThe dangerous part was not only the volume.
It was the combination of backlog replay, parser warning storms, and a Fluent Bit collector running with memory buffering only.
Once the collector got pushed over its cgroup memory limit, the LXC was OOM-killed and the logging path stopped.
That is a very annoying way to learn a good lesson.
The collector did not fail because the architecture was too complex.
It failed because I treated a new log source like “just another input” instead of treating it like a production deploy.
The Boring Diagram Was the Useful Part
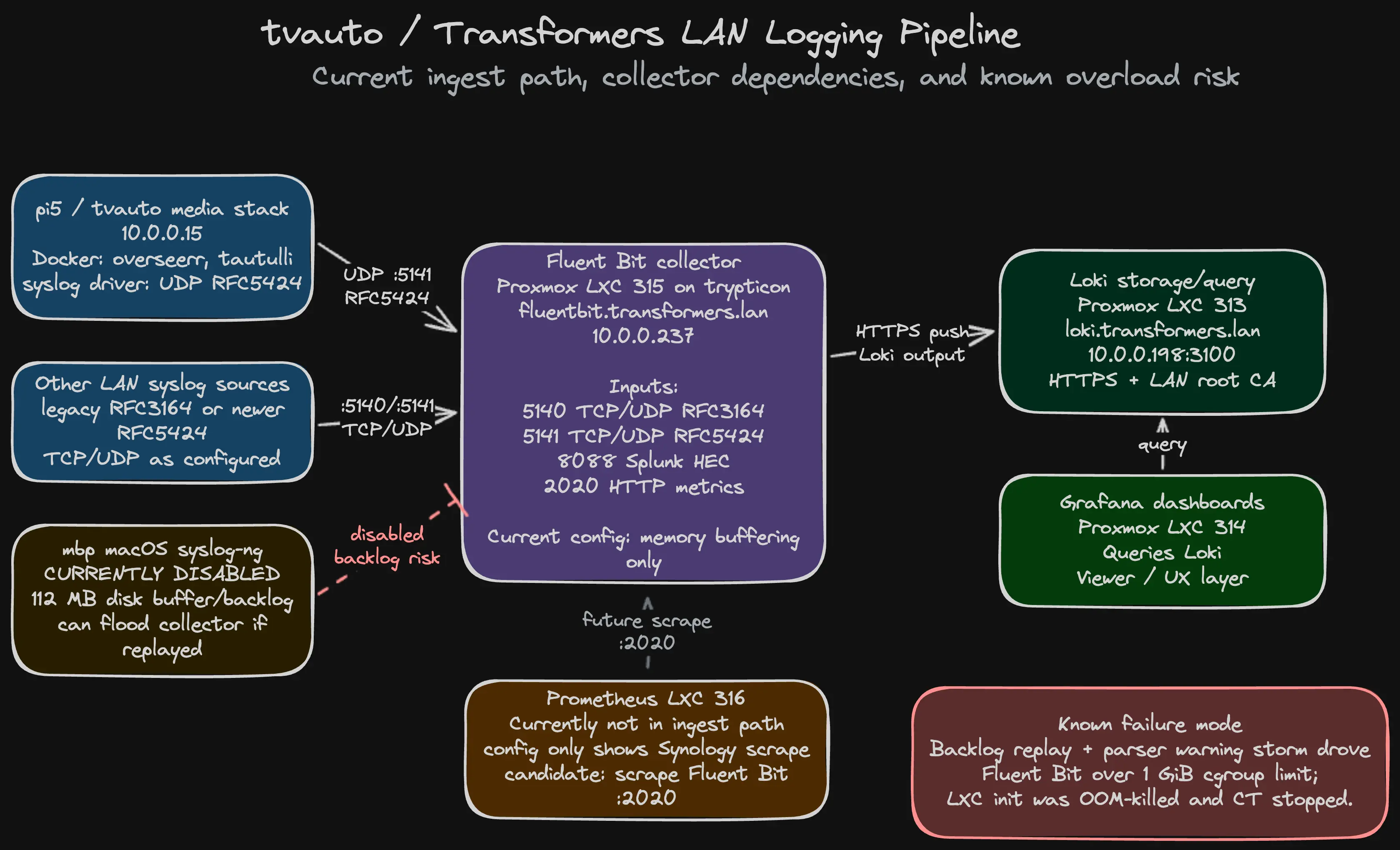
The actual sketch that caught the weak point: Fluent Bit was the central choke point, and the disabled macOS syslog-ng path had enough backlog/replay risk to take the collector down if re-enabled without guardrails.
The most useful artifact from this was not a fancy dashboard.
It was the boring drawing.
The diagram forced me to separate what was actually in the ingest path from what was merely nearby:
- Fluent Bit is the central choke point.
- Loki is storage and query, not protection against ingest overload.
- Grafana is the viewer, not the pipeline.
- Prometheus is a future scrape candidate, not part of the current syslog path.
- The disabled macOS source is still a known risk if re-enabled without guardrails.
That distinction matters because dashboards can make a system feel finished before the ingest path is actually durable.
A diagram makes the weak point visible.
The Lesson: Visibility Has an Ingest Cost
In logging, especially security-adjacent logging, “don’t leave data on the floor” is a good principle.
But it is not the only principle.
A better version is:
Do not leave important data on the floor, but do not ship more than your ingest path can survive.
That second half matters.
A small Fluent Bit collector can be perfectly fine for normal LAN syslog traffic. It can also fall over fast when one source starts replaying a backlog or emitting logs in a format that creates constant parser warnings.
The dashboard does not matter if the collector is dead.
The retention policy does not matter if the logs never make it to Loki.
The security signal does not matter if the ingest path becomes the outage.
What I Would Change Before Enabling the Mac Source Again
Before I turn the macOS syslog-ng path back on, I want guardrails in place.
At minimum:
- disk buffering where replay is possible
- rate limits on noisy sources
- parser validation before sending everything into the main collector
- memory limits that match the expected burst size
- fewer warning storms from known-bad formats
- separate labels or routes for experimental sources
- a way to pause or isolate a single bad source without taking down the collector
The important part is not any one specific knob.
The important part is admitting that every new source changes the blast radius.
If a machine can replay a large backlog, it is not “just a client.”
It is a potential stress test.
Practical Logging Beats Heroic Logging
It is tempting to think the mature logging setup is the one that collects everything.
I am starting to think the mature setup is the one that knows what not to collect yet.
Or at least what not to collect until the path can handle it.
That means starting boring:
- Add one source.
- Watch volume.
- Watch parser errors.
- Watch collector memory.
- Confirm labels and queries are useful.
- Only then add the next source.
That is slower than pointing every box at syslog and hoping for the best.
It is also much less likely to turn observability into another service you have to recover.
The Takeaway
Security wants all the data.
Infrastructure wants to stay alive.
Good logging lives in the tension between those two.
The lesson from this little Fluent Bit/Loki incident was not “collect less forever.”
It was:
Collect deliberately. Buffer what can burst. Rate-limit what can scream. Validate before you trust a new source. Then dashboard it.
More logs can be useful.
More logs can also be the thing that takes logging down.
Choose your firehose carefully.